 پرش به محتوا
پرش به محتوا 



در چند سال گذشته شاهد استفاده بسیار زیاد توسعه دهندگان و شرکتهای مختلف از کانتینرها بودهایم و این بدان معناست که رویه استقرار اپلیکیشنها تغییرات بسیار زیادی به خود دیده است. یکی از اصلیترین نرمافزارها و تکنولوژیهایی که در این سالها نیز به این رویه کمک کرده است Kubernetes بوده است.
کوبرنتیز به صورت کلی، ویژگیها و امکانات بسیار زیادی را برای توسعه دهندگان و متخصصین DevOps ایجاد کرده است، بررسیهای خودکار سلامت ایمیجها، Zero Downtime، مدیریت ایمیجهای مختلف و… تنها چند مورد کلی از امکاناتیست که کوبرنتیز برای جامعه متخصص ایجاد کرده و مطمئنا تمامی این موارد نیز روی محبوبیت این تکنولوژی تاثیر گذاشته است.
بنابراین اکنون میتوان نتیجه گرفت که با کمک کوبرنتیز همه چیز قابلیت دسترسی بالایی پیدا کرده است. اما به عنوان یک نکته مهم این را بگوییم که اگر شما بخواهید، پیادهسازی موفق و تمام عیاری از کوبرنتیز ایجاد کنید، نیاز دارید که به خوبی با این تکنولوژی آشنایی پیدا کنید، در غیر اینصورت تنها با نصب کردن اولیه کوبرنتیز، همه کارها به صورت خودکار انجام نخواهد شد.
هدفی که در این مطلب از وبلاگ پچیم داریم این است که بفهمیم چگونه به Zero-Downtime اپلیکیشنها در کوبرنتیز برسیم. برای روشن شدن قضیه هم بگوییم که منظور از Zero-Downtime به صفر رساندن نرخ متوقف شدن یا از کار افتادن اپلیکیشن است.
موقعیت ایمیجها در کانتینر
اگر مدتیست که از داکر استفاده میکنید، مطمئنا تا الان با استفاده کردن از ایمیجها و کانتینرها آشنایی پیدا کردهاید و با این موارد نیز به صورت عملی کار کردهاید. با این حال در فرایند تولید و ایجاد اپلیکیشن (نه در مرحله تست و یادگیری) اگر که صاحب ایمیجها نباشید مطمئنا دوست ندارید که روی ایمیج رجیستری کنترل نشده و ریموت تمرکز کنید. دلیل این موضوع نیز واضح است:
- ممکن است دسترسی به ایمیج رجیستری را به هر دلیلی از دست بدهید که اینکار در محیط اجرایی باعث ایجاد خطای ImagePullBackOff میشود.
- ایمیج تگی که از آن استفاده میکنید ممکن است حذف شود.
- محتوای ایمیج تغییر کند اما تگ ایمیج به صورت ثابت باقی بماند. در این حالت رفتار ایمیجها در نودهای مختلف کلاستر شما نیز به صورت یکسان نخواهد بود.
- ممکن است ایمیج مورد نظر با نیازمندیهای امنیتی شما سازگاری نداشته باشد.
برای این مشکلات چندین راهحل وجود دارد. یکی از این موارد سینک کردن ایمیج کانتینرها با رجیستری خودتان است. در این حالت ما ایمیجها را روی تمام کلاسترها قرار داده و از قسمت رجیستری تغییرات را اعمال میکنیم. در نهایت پس از ایجاد تغییر، ایمیجها و کلاسترهای مختلف به خوبی با همدیگر سینک میشوند
تعداد پاد یا Podها (نمونههای اپلیکیشن یا Application Instance)
ممکن است قبلا هم این نکته را شنیده باشید اما نیاز است که ما یک بار دیگر آن را تکرار کنیم: برای اینکه بتوانید سطح بالایی از در دسترس بودن را ارائه کنید، شما حداقل به دو Replica در کوبرنتیز نیاز دارید. منظور از Replica کلونهاییست که به Self-Healing در پادها کمک میکند. در نتیجه اگر بخواهیم سطح در دسترس بودن یا Availability را افزایش دهیم انجام این کار یکی از اساسیترین موارد است. به نمونه زیر دقت کنید:
apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: replicas: 2 # tells deployment to run 2 pods matching the template template: ..
گاهی اوقات از افرادی میشنویم که نیازی به انجام این کار در کوبرنتیز نیست چرا که ما در محیط کوبرنتیز، ویژگی Rolling Updates را در اختیار داریم و کوبرنتیز از این ویژگی به صورت مداوم استفاده میکند. در نتیجه قبل از اینکه یک نمونه خاموش شود یا از بین برود یک نمونه دیگر شروع به کار میکند. این موضوع درست است اما این حالت تنها زمانی مورد استفاده قرار میگیرد که بروزرسانیهای سطح استقرار یا Deployment صورت بگیرد.
در شرایط و سناریوهای زیر، راهحلی که این افراد از آن صحبت میکنند نمیتواند عملی شود:
- زمانی که Nodeی که اپلیکیشن شما روی آن اجرا میشود را از دست دهید. در این حالت پاد شما باید از ابتدا کار خود را شروع کند.
- زمانی که کلاستر شما Node Drain را درخواست کند. برای مثال در زمان بروزرسانی و ارتقا EKS یا تغییر نوع نود این اتفاق میافتد.
بر اساس دو دلیلی که در بالا به آنها اشاره کردیم شما حداقل به دو نمونه یا Instance برای جلوگیری از Downtime نیاز دارید.
آشنایی با مفهوم PodDisruptionBudget
PDB یا PodDisruptionBudget یک المان کوبرنتیز است که تعداد پادهای غیر قابل دسترس در مرحله استقرار و نگهداری را ارائه میکند. در این حالت شما با آگاهی از وضعیت پادها میتوانید به صورت درست از وضعیت اپلیکیشنتان خبردار شوید و بدانید که چه مشکلاتی برای پادهایتان وجود دارد.
بیایید یک مثال را در نظر بگیرید: شرایطی را تصور کنید که اپلیکیشن من سه پاد یا نمونه را در اختیار دارد. در این مثال براساس تجربیاتی که در این زمینه به دست آوردهام تصمیم دارم تا حداقل دو پاد را در اختیار داشته باشم. در این حالت اگر من PDB را اجرا کنم میتوانم مطمئن شوم که دو پاد در حال اجرا هستند.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-pdb
spec:
maxUnavailable: 1
selector:
matchLabels:
app: my-app در این حالت من میتوانم از اجرا شدن درست پادها اطمینان حاصل کنم و در نتیجه نرخ Downtime را کاهش بدهم.
استراتژیهای استقرار یا Deployment
به صورت کلی دو استراتژی استقرار در دنیای کوبرنتیز وجود دارد:
استراتژی RollingUpdate: استراتژی پیشفرض کوبرنتیز که باعث میشود فرایند استقرار و دیپلوی بسیار ساده شود.
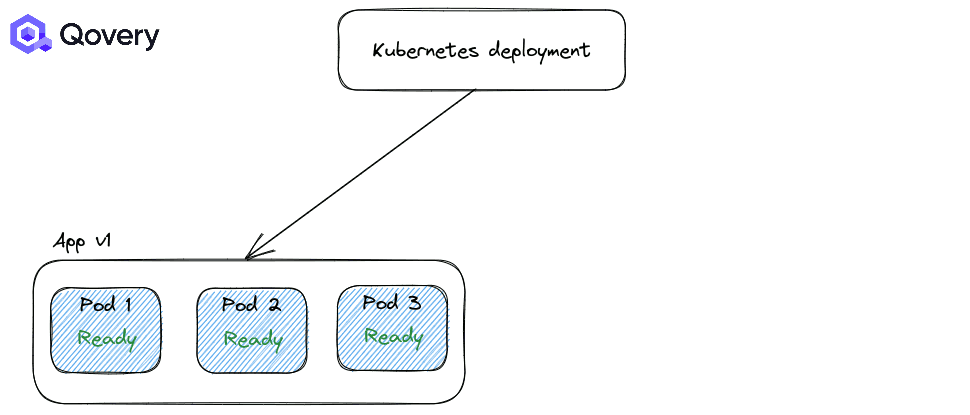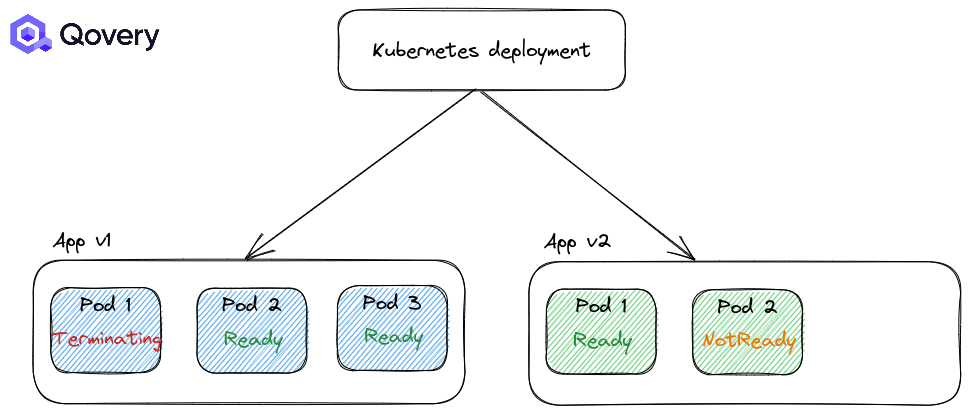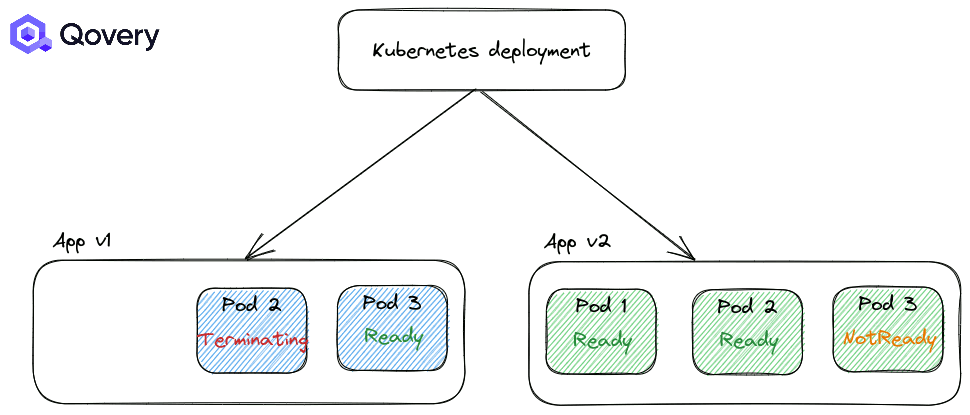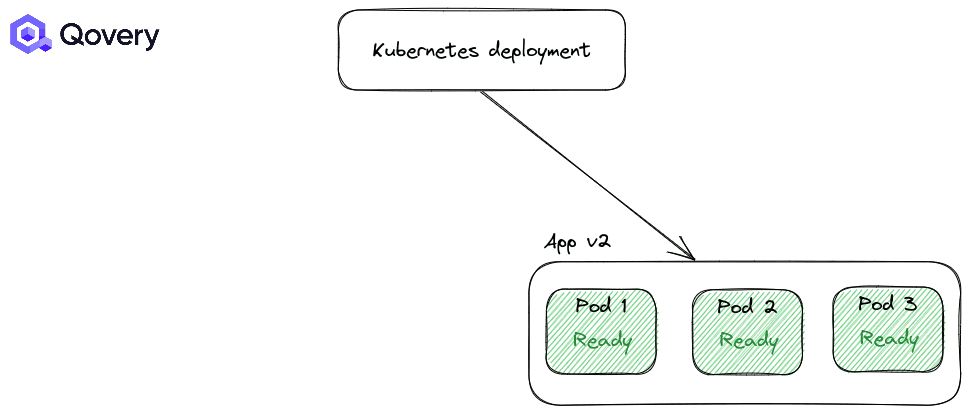
استراتژی Recreate: در این استراتژی اپلیکیشنها زمانی که قرار است نسخه جدیدی عرضه شود به زور بسته میشوند.
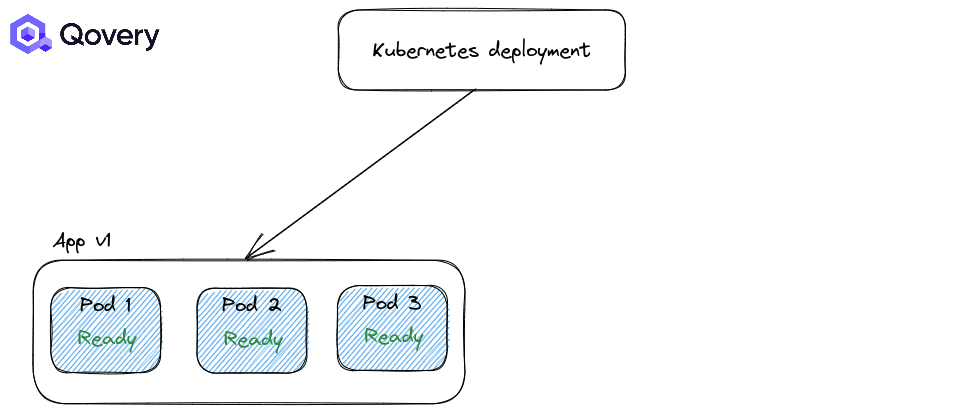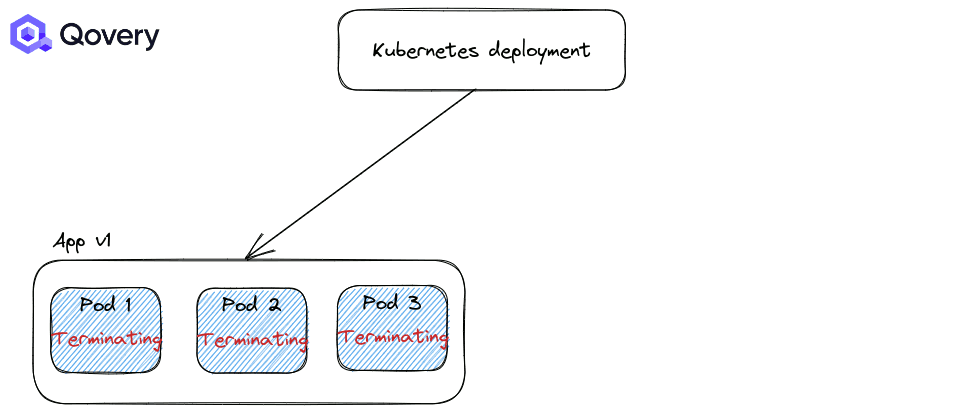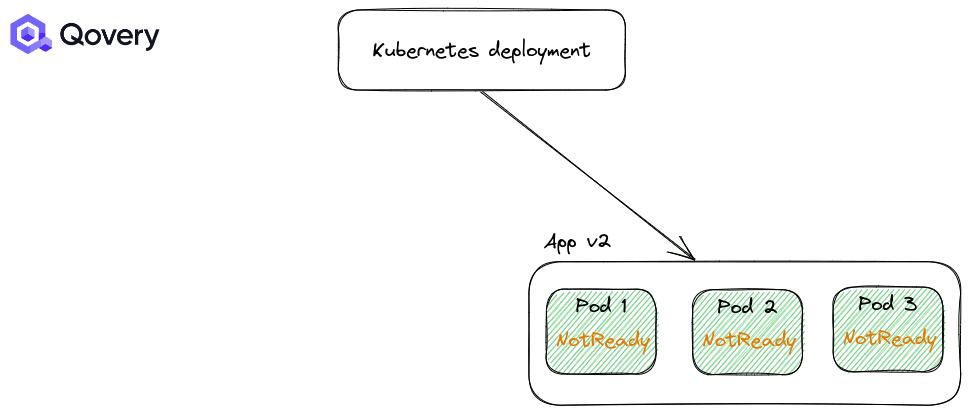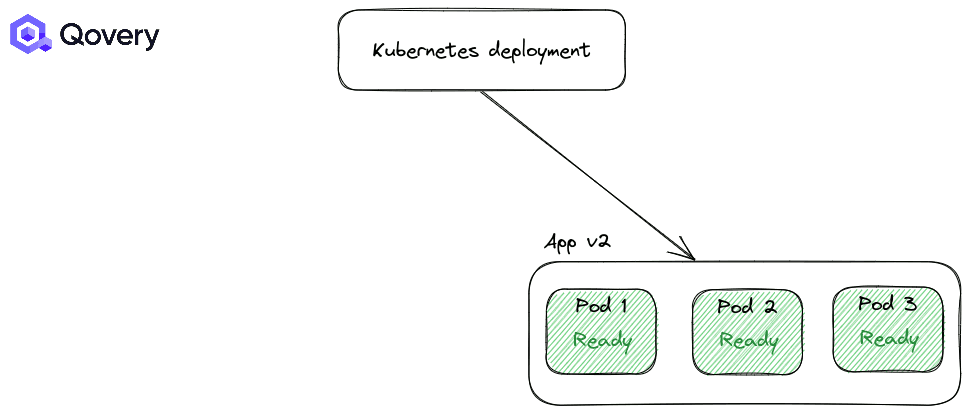
به صورت پیشفرض استراتژی اول یعنی RollingUpdate همواره اعمال میشود. اما شما میتوانید نحوه انجام این استراتژی را با استفاده از Max Unavailable و Max Surge تغییر دهید.
زمانی که شما با حجم ترافیکی سنگینی روبرو هستید و میخواهید کنترل سرعت دیپلوی کردن را در دست بگیرید و کارایی را بالا ببرید استفاده کردن از این گزینهها میتواند بسیار کاربردی باشد.
استقرار بوسیله Automatic Rollback
در دنیای کوبرنتیز Automatic Rollback به صورت یک ویژگی یا گزینه قابل دسترس وجود ندارد. شما برای استفاده از این حالت نیاز دارید که از ابزارهای دیگری مانند Helm، ArgoCD و Spinnaker استفاده کنید. با استفاده از این ویژگی زمانی که اپلیکیشن شما نتواند به درستی اجرا شود، ترافیک الکی به سرور ارسال نشده و همه چیز به حالت قبلی باز میگردد. البته اگر قرار است از ابزارهای دیگری استفاده کنید مطمئن شوید که به درستی همه چیز را پیکربندی میکنید در غیر اینصورت ممکن است مشکلات مختلفی بوجود بیاید. بنابراین با آگاهی کامل سراغ این نرم افزارها بروید.
Probe و نقش آن در Zero-Downtime
Probe یکی از ویژگیهاییست که معمولا در دنیای کوبرنتیز کمتر به آن توجه میشود. اما این را بسیار واضح بگوییم که Probeها نقش بسیار مثبت و مهمی در رسیدن به Zero-Downtime دارند. Probe به شما کمک میکنند تا از سلامت اپلیکیشنتان مطمئن شوید. به صورت کلی دو مورد مهم در دنیای Probeها وجود دارد که شامل Liveness و Readiness میشود. در زیر شمای کلی هر دو این سرویسها را میتوانید مشاهده کنید:

Liveness به شما این اطمینان را میدهد که اپلیکیشن شما در وضعیت Alive قرار گرفته است یا نه. اگر عملیاتی که Liveness در نظر دارد به صورت موفق صورت نگیرد دو حالت زیر فعال میشود:
- ترافیکهای مربوط به پاد متوقف شده و ترافیکی دریافت نمیگردد.
- پاد ریستارت (راه اندازی مجدد) شده و سعی میکند تا به وضعیت پایدار و سالم بازگردد.
Readiness وظیفه دارد وضعیت ارسال ترافیک به پادها را بررسی کند. (اینکه آیا به پاد ترافیکی ارسال شود یا خیر). در این شرایط دو حالت کلی پیش خواهد آمد:
- اگر وضعیت ترافیک شما با مشکل روبرو شود (در حالتی که Liveness پاسخگو است) و اپلیکیشن کُند شود، در این حالت Readiness تصمیم میگیرد که ارسال ترافیک به سمت اپلیکیشن را متوقف نماید. این کار برای بازگشت به حالت پایدار و سالم اتفاق میافتد.
- Readiness در صورتی که پاد به وی پاسخگو نباشد، آن را ریستارت نمیکند. در این حالت نیز تنها کاری که انجام میگیرید متوقف کردن ترافیک ارسالی خواهد بود.
به یاد داشته باشید که در هر حالتی، پیکربندی Prob یک کار مهم و ضروری است. بنابراین از درستی کار کردن این سرویس مطمئن شوید.
تاخیر اولیه در زمان بوت
در بازههای زمانی مختلف و براساس اتفاقات مختلف، زمان بوت اولیه ممکن است با تاخیرهای مختلفی روبرو شود. در زیر به چند حالت که باعث این موضوع میشود خواهیم پرداخت:
- اپلیکیشن شما از سیپییو به صورت غیر عادی استفاده کرده و حجم پردازش زیادی را اشغال میکند. برای مثال اپلیکیشنهای مبتنی بر SpringBoot این مشکل را دارند.
- تغییراتی که جدیدا روی اپلیکیشن اعمال کردهاید نیاز به پردازش بیشتری داشته و از این نظر سرعت بوت شدن را کند کرده است. معمولا زمانی که ویژگی جدیدی به اپلیکیشن اضافه میکنید و منابع سختافزاری جدیدی را به آن تخصیص نمیدهید این اتفاق میافتد.
- مشکلاتی که در سمت دیتابیس وجود دارد یکی دیگر از دلایل این موضوع است. زمانی که اپلیکیشن شما آماده کار کردن باشد اما با دیتابیسی که در فرایند اجرا مشکل دارد مجبور باشد که ارتباط بگیرد، در نهایت کل کارایی را کاهش میدهد.
سناریوهای بسیار دیگری هستند که در نهایت همگی باعث ایجاد تاخیر در بوت شدن اپلیکیشن شما میشوند. زمانی که با چنین مشکلی روبرو شدید مقدار initialDelaySeconds را به صورت زیر بروزرسانی کنید.
livenessProbe: initialDelaySeconds: 60 httpGet: ...
همچنین مشکلی که باعث این موضوع شده را حتما پیدا کرده و آن را حل نمایید.
بررسی Pod Anti-affinity
Pod Anti-affinity سرویسیست که به شما این امکان را میدهد تا از داشتن چندین نمونه از یک پاد در یک نود جلوگیری کنید. زمانی که یک نود داشته باشید و آن از کار بیافتد، تمام نمونههایی که روی آن نود دارید نیز دچار مشکل میشوند و در نتیجه اپلیکیشن شما با Downtime روبرو خواهد شد.
برای اجتناب از این حالت، شما میتوانید از کوبرنتیز بخواهید که تمام پادها را روی یک نود قرار ندهد. در دنیای کوبرنتیز دو حالت Anti-affinity وجود دارد که در زیر هر دو این موارد را معرفی میکنیم:
- Soft Anti-affinity: این مورد با استفاده از دستور preferredDuringSchedulingIgnoredDuringExecution تمام تلاش خود را میکند تا از بروز چنین مشکلی جلوگیری کند، اما اگر نتوانست (بدلیل کمبود منابع) روی همان نود، دو نمونه از پاد را اضافه میکند. این نسخه از Anti-affinity بسیار مقرون به صرفه بوده و در بیشتر حالتها میتواند کار شما را راه بیاندازد.
- Hard Anti-Affinity: این مورد با استفاده از دستور requiredDuringSchedulingIgnoredDuringExecution نسخهای سختگیرتر بوده و اجازه قرار دادن چندین پاد روی یک نود را به شما نمیدهد. در این حالت شما برای هر پاد نیاز به یک نود جداگانه دارید. این حالت از Anti-affinity مقرون به صرفه نبوده و هزینههای مالی بسیاری را برای شما ایجاد میکند.
در محیط کوبرنتیز استفاده از این موارد به شکل زیر خواهد بود:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone منابع
منابع موجود یکی از مرسومترین مشکلاتیست که برای اجرای اپلیکیشنها بوجود میآید. زمانی که شما منابع کافی را در اختیار اپلیکیشنتان قرار ندهید، مشکلات زیر ایجاد خواهند شد:
- مشکل OOM یا Out Of Memory که در این حالت اپلیکیشن شما متوقف شده و تمام ارتباطات نیز بسته میشود. در واقع اگر این خطا بوجود بیاید اپلیکیشن شما نخواهد توانست که سرویسی را ارائه دهد.
- مشکل استفاده از CPU یکی دیگر از مواردیست که در نهایت باعث از کار افتادن اپلیکیشن شما میشود. در این حالت منابع موجود برای CPU نمیتوانند ویژگیهای اپلیکیشن را پیادهسازی بکنند و در نهایت اپلیکیشن شما کُند شده و در یک مرحلهای به کلی از کار میافتد.
مقایسدهی خودکار
مقیاسدهی خودکار یکی از بهترین روشها برای جلوگیری از Downtime در مواقع مختلف است. در این حالت زمانی که بخواهید تغییرات جدیدی را به اپلیکیشن اعمال کنید، نیازی ندارید که به صورت دستی منابع جدید را به آن اختصاص دهید، بلکه براساس نیاز اپلیکیشن، منابع از طریق سرویس دهنده به صورت خودکار به اپلیکیشن شما تخصیص داده میشود.
البته این کار تنها بسته به سرویسدهنده شما نیست بلکه باید خودتان نیز کوبرنتیزی که اپلیکیشن روی آن قرار گرفته را به خوبی پیکربندی کنید در غیر اینصورت فرایند مقیاسدهی خودکار صورت نمیگیرد. در زیر میتوانید یک نمونه از پیکربندی کوبرنتیز برای مقیاسدهی خودکار را مشاهده کنید:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
spec:
...
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 در پایان
کوبرنتیز یکی از بهترین دوستهای شما برای مدیریت اپلیکیشنهای مبتنی بر کلود است اما تا زمانی که نتوانید به خوبی آن را براساس نیازهای خودتان پیکربندی نکنید، نخواهد توانست کار چندان زیادی را انجام دهد. به صورت خلاصه بگویم که زمانی که اپلیکیشنتان را راهاندازی میکنید باید تا جای ممکن نرخ Downtime را کاهش دهید در غیر اینصورت مشکلات جبرانناپذیری برای کسب و کار شما بوجود خواهد آمد.
در این مقاله سعی کردیم تا شما را با مواردی آشنا کنیم که در نهایت باعث میشود تا ایده Zero Downtime امکان پذیر شود.