 پرش به محتوا
پرش به محتوا 



دسترسی پایدار به سرویسها و سامانههای نرمافزاری، از اصلیترین نیازهای کسبوکارهای امروزی است. زمانی که خدمات آنلاین، ستون فقرات فعالیت یک سازمان را تشکیل میدهند، هرگونه وقفه یا خرابی میتواند منجر به زیان مالی، از دست دادن اعتماد کاربران و اختلال در عملیات شود. مفاهیمی مانند دسترسپذیری بالا (High Availability)، تحملپذیری خطا (Fault Tolerance) و… در همین بستر مطرح میشوند.
در این مطلب قرار است به شکلی دقیق و ساختارمند، به معرفی این مفاهیم، تمایز میان آنها و مزایای معماریهای مبتنی بر دسترسپذیری بالا بپردازد.
جدول محتواها
دسترسپذیری بالا چیست؟
دسترسپذیری بالا (High Availability) به توانایی یک سیستم برای ادامهی عملکرد بدون وقفه، حتی در مواجهه با خرابی بخشی از زیرساخت، اشاره دارد. هدف از پیادهسازی High Availability این است که سرویسها در دسترس کاربران باقی بمانند، حتی در شرایطی که یکی از مؤلفهها دچار مشکل شود.
دسترسپذیری معمولاً با درصدی از زمان فعالبودن سیستم در یک بازهی مشخص سنجیده میشود. برای نمونه، دسترسپذیری ۹۹٫۹٪ (Three Nines) معادل حدود ۸٫۷ ساعت داونتایم در سال است، در حالی که ۹۹٫۹۹۹٪ (Five Nines) تنها ۵ دقیقه داونتایم در سال را مجاز میداند. این ارقام برای سامانههایی که وابستگی شدیدی به پایداری دارند، مانند خدمات بانکی یا زیرساختهای ابری، اهمیت حیاتی دارد.
دسترسپذیری بالا بهجای تلاش برای حذف کامل خطاها، بر طراحی سیستمی متمرکز است که بتواند خطاها را جذب کرده و به فعالیت خود ادامه دهد.

معماری High Availability
معماریهایی که برای دسترسپذیری بالا طراحی میشوند، مجموعهای از روشها و الگوهای مهندسی سیستم را بهکار میگیرند تا بتوانند در برابر خرابیها مقاومت نشان دهند و عملکرد سامانه را حفظ کنند.
مهمترین ویژگیهای معماری High Availability عبارتاند از:
۱. افزونگی (Redundancy)
یکی از ارکان اصلی در این معماری، افزونگی منابع است. سرورها، دیتابیسها، شبکهها و سایر اجزای بحرانی بهصورت تکراری یا چند نسخهای پیادهسازی میشوند تا در صورت خرابی یکی، دیگری بلافاصله جایگزین شود. این افزونگی ممکن است به شکل Active-Passive یا Active-Active اجرا گردد.
۲. Failover خودکار
در معماریهای High Availability، مکانیسمهایی برای انتقال خودکار بار از جزء معیوب به جزء سالم (Failover) وجود دارد. این فرآیند باید بدون دخالت انسانی و در کمترین زمان ممکن انجام شود تا کاربران اختلالی احساس نکنند.
۳. تعادل بار (Load Balancing)
برای اطمینان از استفادهی بهینه از منابع و کاهش فشار روی یک نقطهی خاص، از Load Balancerها استفاده میشود. این ابزارها درخواستهای ورودی را میان چند سرور توزیع میکنند و در صورت از کار افتادن یک سرور، بهطور خودکار مسیرها را به سرورهای باقیمانده هدایت مینمایند.
۴. حذف Single Point of Failure
معماری High Availability بهگونهای طراحی میشود که هیچ جزء یکتایی (Single Point of Failure) وجود نداشته باشد. این یعنی خرابی هیچ مؤلفهای نباید به ازکارافتادن کل سیستم منجر شود.
۵. پایش و مانیتورینگ مداوم
برای واکنش سریع به هرگونه مشکل، سامانه باید بهطور دائمی پایش شود. مانیتورینگ مناسب، دادههایی دربارهی وضعیت سلامت اجزای مختلف فراهم میکند تا Failover یا هشدار بهموقع فعال شود.
تحملپذیری خطا چیست؟ (Fault Tolerance)
تحملپذیری خطا به توانایی یک سیستم برای ادامهی عملکرد بدون هیچگونه وقفه یا اختلال قابل تشخیص حتی در صورت بروز خرابی سختافزاری یا نرمافزاری اشاره دارد. در واقع، برخلاف High Availability که ممکن است لحظهای تأخیر یا وقفه برای جابجایی به جزء سالم داشته باشد، در سیستمهای Fault Tolerant این وقفه وجود ندارد یا کاملاً نامحسوس است.
تفاوت Fault Tolerance با High Availability
| ویژگی | High Availability | Fault Tolerance |
|---|---|---|
| نوع طراحی | مبتنی بر افزونگی و failover | مبتنی بر اجرای همزمان چند نسخه (replication) |
| واکنش به خرابی | انتقال بار به جزء سالم | ادامه بیوقفه بدون انتقال |
| پیچیدگی و هزینه | متوسط | بالا (سختافزار و نرمافزار تخصصی) |
| داونتایم | ممکن است چند ثانیه وجود داشته باشد | صفر یا نزدیک به صفر |
سیستمهای Fault Tolerant اغلب در حوزههایی با نیازهای حیاتی به استمرار عملکرد، مانند سامانههای کنترل پرواز، بانکهای اطلاعاتی real-time مالی، یا زیرساختهای مخابراتی استفاده میشوند. آنها معمولاً نیازمند زیرساختهای موازی، سختافزارهای خاص و الگوریتمهای تطبیقی هستند.
بهطور خلاصه، High Availability یعنی سیستم در بیشتر زمانها در دسترس است، اما Fault Tolerance یعنی سیستم همیشه در دسترس است حتی در لحظهی وقوع خطا.
افزونگی سیستم (System Redundancy)
افزونگی (Redundancy) به معنای فراهمکردن نسخههای جایگزین از اجزای حیاتی سیستم است، بهنحوی که در صورت بروز خرابی در یک جزء، جزء دیگر بتواند بدون وقفه جایگزین آن شود. این اصل بنیادیترین عنصر در طراحی سیستمهایی با دسترسپذیری بالا است.
انواع افزونگی
- افزونگی سختافزاری: استفاده از چند سرور، منابع ذخیرهسازی یا تجهیزات شبکهی تکراری که بتوانند نقش یکدیگر را در مواقع خرابی بر عهده بگیرند.
- افزونگی نرمافزاری: اجرای چند نسخهی مستقل از یک سرویس یا میکروسرویس در نقاط مختلف.
- افزونگی جغرافیایی (Geo-Redundancy): استقرار اجزای کلیدی در دیتاسنترهای مختلف، معمولاً در شهرها یا کشورهای مختلف، برای محافظت در برابر وقایع گسترده مانند زلزله، آتشسوزی یا قطعی برق سراسری.
سطوح افزونگی
افزونگی میتواند در سطوح مختلف اعمال شود: از سطح سرور و دیتابیس تا شبکه و حتی لایهی نرمافزار. هرچه سطح افزونگی بالاتر باشد، پیچیدگی مدیریت و هزینهی پیادهسازی نیز افزایش خواهد یافت.
مزایا
- افزایش تابآوری سیستم در برابر خرابیها
- کاهش زمان توقف خدمات
- امکان اجرای Failover خودکار
- پیشنیاز برنامههای Disaster Recovery
افزونگی اگرچه هزینهبر است، اما در بسیاری از حوزهها یک الزام محسوب میشود، بهویژه در سامانههایی که هر لحظه داونتایم میتواند زیانهای سنگینی در پی داشته باشد.
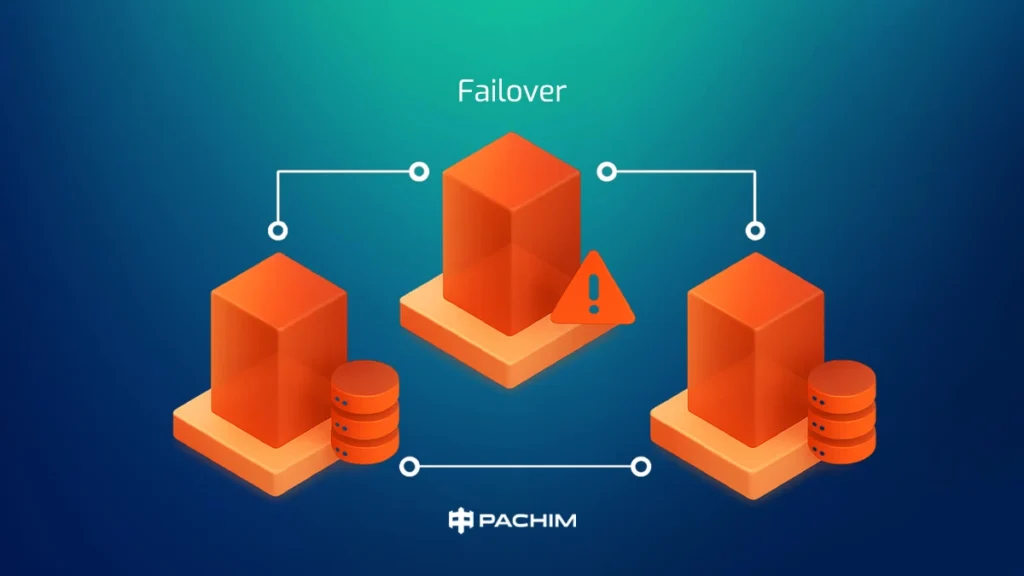
Failover چیست؟
Failover فرآیندی است که در آن، در صورت خرابی یا در دسترس نبودن یکی از اجزای حیاتی سیستم، بهطور خودکار یا دستی عملیات و بار کاری به جزء پشتیبان یا جایگزین منتقل میشود. این مفهوم یکی از پایههای اساسی دسترسپذیری بالا (High Availability) است.
هدف از Failover
هدف اصلی Failover حفظ تداوم عملکرد سامانه، بدون نیاز به مداخلهی انسانی یا با حداقل تأخیر ممکن است. این فرآیند معمولاً در سطح سرورها، دیتابیسها، ماشینهای مجازی، یا سرویسهای نرمافزاری پیادهسازی میشود.
انواع Failover
- خودکار (Automatic Failover): سیستم با استفاده از ابزارهای مانیتورینگ و تحلیل سلامت (Health Checks) خرابی را شناسایی میکند و بدون مداخلهی انسان، سرویس را به گره سالم منتقل مینماید.
- دستی (Manual Failover): در برخی زیرساختها، بهدلایل امنیتی یا طراحی، انتقال به گره جایگزین توسط اپراتور انسانی انجام میشود.
مثال کاربردی
فرض کنید یک سرویس وب بر روی دو سرور مستقل راهاندازی شده باشد. اگر سرور اول دچار مشکل شود (مثلاً به دلیل خرابی سختافزاری یا قطع ارتباط شبکه)، Load Balancer بهسرعت تشخیص میدهد که پاسخگویی از این سرور ممکن نیست و ترافیک را به سرور دوم هدایت میکند. این انتقال، همان فرآیند Failover است.
تفاوت با Fault Tolerance
Failover معمولاً مستلزم یک جابجایی آشکار و قابل اندازهگیری از سیستم معیوب به سیستم سالم است، حتی اگر این جابجایی در چند ثانیه انجام شود. در مقابل، Fault Tolerance به معنای ادامهی بیوقفهی عملکرد، بدون هیچگونه جابجایی یا تأخیر است.
آپتایم سرور (Server Uptime)
آپتایم (Uptime) به مدت زمانی گفته میشود که یک سرور یا سرویس بهطور پیوسته و بدون وقفه در حال فعالیت و پاسخگویی است. این معیار یکی از شاخصهای اصلی برای ارزیابی پایداری و قابلیت اعتماد یک سامانه است.
اهمیت آپتایم
در بسترهای ابری، خدمات مالی، تجارت الکترونیک و دیگر سامانههای وابسته به اتصال دائمی، حتی چند دقیقه داونتایم میتواند منجر به زیان اقتصادی، نقض SLA (توافقنامه سطح خدمات)، از دست رفتن دادهها یا کاهش اعتماد کاربران شود.
چگونه آپتایم اندازهگیری میشود؟
آپتایم معمولاً بهصورت درصدی از کل زمان ممکن در یک بازه (مثلاً یک سال) بیان میشود:
| سطح آپتایم | زمان مجاز داونتایم در سال |
|---|---|
| 99% | ~3.65 روز |
| 99.9% | ~8.7 ساعت |
| 99.99% | ~52 دقیقه |
| 99.999% | ~5 دقیقه |
چگونه به آپتایم بالا دست یابیم؟
برای دستیابی به آپتایم بالا، رعایت مجموعهای از اصول ضروری است:
- استفاده از معماری High Availability
- پیادهسازی Failover و Load Balancer
- مانیتورینگ ۲۴/۷ سیستمها
- نگهداری پیشگیرانه از سختافزار
- اجرای استقرار بدون داونتایم
در پایان
دسترسپذیری بالا (High Availability) یکی از اصول حیاتی در طراحی سامانههای مدرن است که تضمین میکند سرویسها حتی در مواجهه با خرابیها به کار خود ادامه دهند. افزونگی سیستم، تعادل بار، و فرآیند Failover نقش کلیدی در حفظ این دسترسپذیری دارند. در مقایسه با تحملپذیری خطا (Fault Tolerance)، High Availability ممکن است شامل لحظاتی از وقفه باشد اما در کل تضمین میکند که داونتایم به حداقل برسد. همچنین، مفاهیمی مانند آپتایم سرور و استقرار بدون داونتایم در کنار معماریهای مقاوم، به سازمانها امکان میدهند خدمات پایدار و قابل اتکایی ارائه کنند.